Publications
2025
 Gaze Beyond the Frame: Forecasting Egocentric 3D Visual SpanIn NeurIPS (Spotlight) , 2025
Gaze Beyond the Frame: Forecasting Egocentric 3D Visual SpanIn NeurIPS (Spotlight) , 2025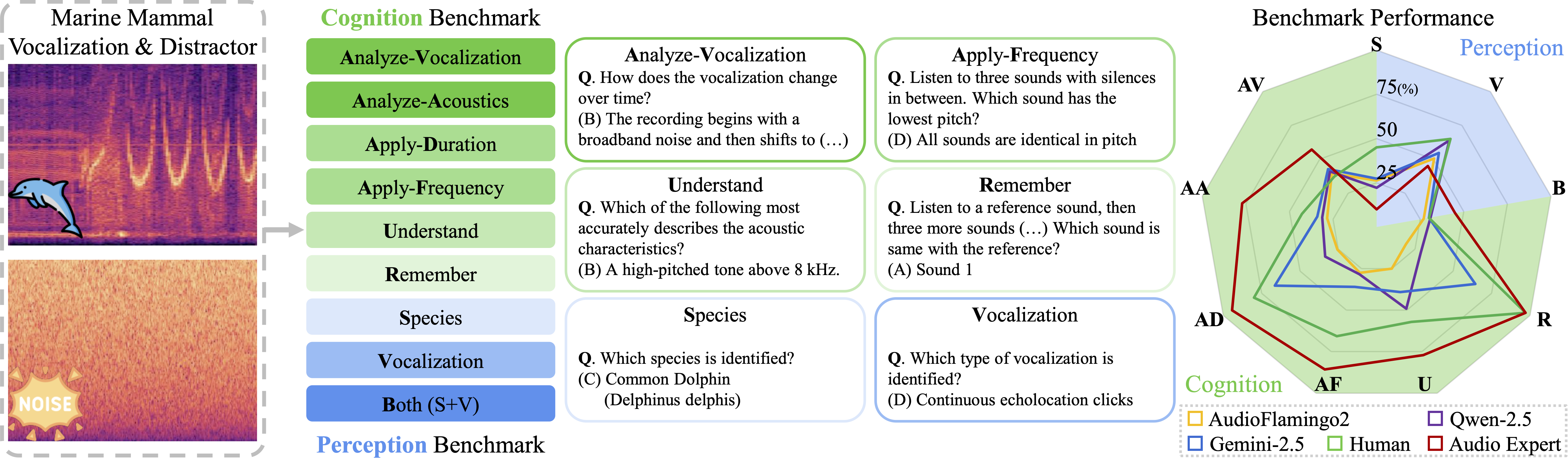 WoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal VocalizationsarXiv preprint arXiv:2508.20976, 2025
WoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal VocalizationsarXiv preprint arXiv:2508.20976, 2025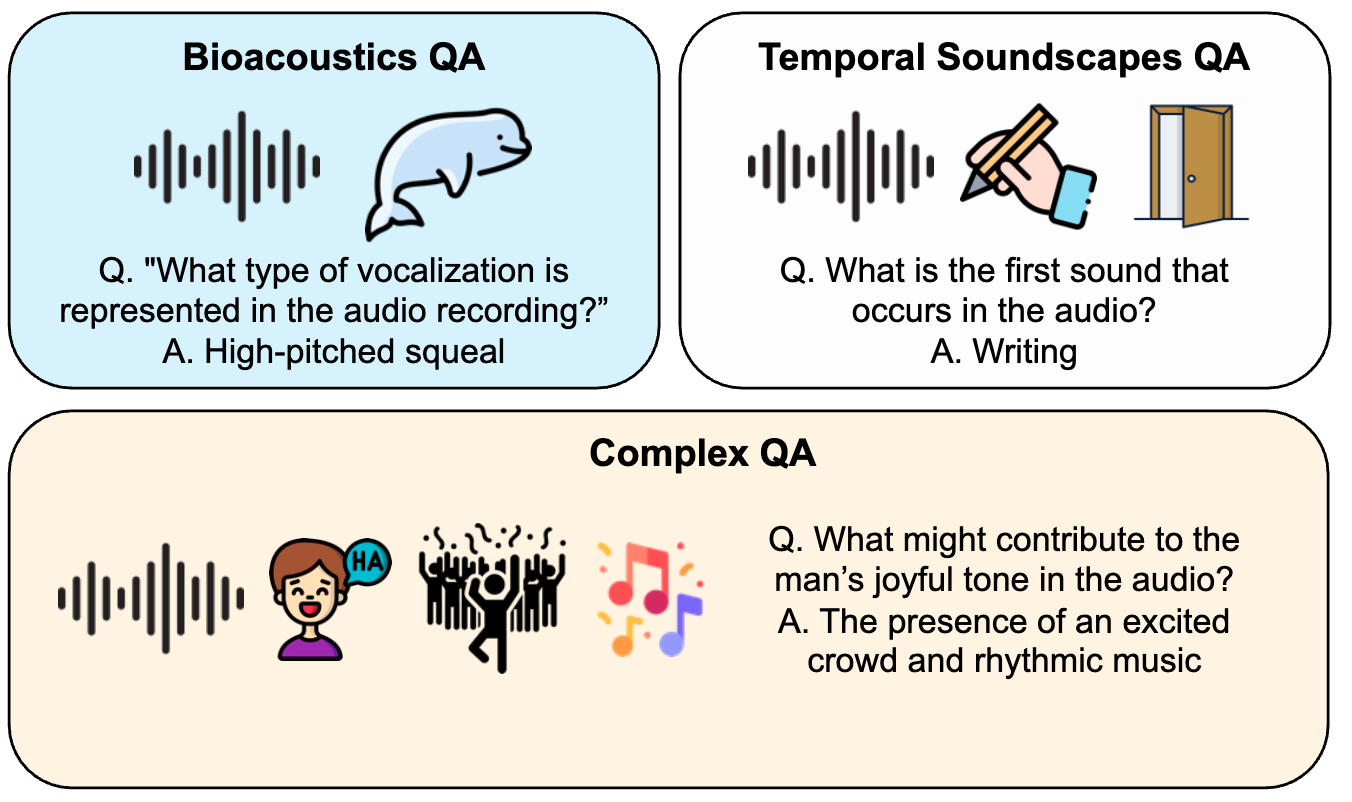 Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 ChallengearXiv preprint arXiv:2505.07365, 2025
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 ChallengearXiv preprint arXiv:2505.07365, 2025




2024
 EnCLAP++: Analyzing the EnCLAP Framework for Optimizing Automated Audio Captioning PerformanceIn DCASE2024 Workshop , 2024
EnCLAP++: Analyzing the EnCLAP Framework for Optimizing Automated Audio Captioning PerformanceIn DCASE2024 Workshop , 2024- Expanding on EnCLAP with Auxiliary Retrieval Model for Automated Audio CaptioningDCASE2024 Challenge Technical Report, 2024
 Learning Semantic Information from Raw Audio Signal Using Both Contextual and Phonetic RepresentationsIn ICASSP , 2024
Learning Semantic Information from Raw Audio Signal Using Both Contextual and Phonetic RepresentationsIn ICASSP , 2024



